

12月9-10日,由全国工商联环境商会主办,以“学习贯彻十九大精神:锻造产业利剑 护卫美丽中国”为主题的“2017中国环保上市公司峰会”在广东肇庆召开。
中科院高性能计算机研究中心主任、博导谭光明在峰会上表示,人工智能成为经济发展的新引擎,还给社会建设带来新机遇。在技术层面也是国际社会各个国家科研机构竞争的高端技术。

中科院高性能计算机研究中心主任、博导 谭光明
以下是演讲实录:
最近在环保应用领域做了一点事情,雾霾检测方向做了一些应用,一些算法研究,跟大家分享一下,后续还有很多事情需要往前推进。
人工智能已经成为国家发展战略的一部分,美国、欧洲、日本等也发展迅速。这些数据能够说明问题,像各领域人工智能公司的创建,如雨后春笋般出现。人工智能成为经济发展的新引擎,还有给社会建设带来新机遇。在技术层面也是国际社会各个国家科研机构竞争的高端技术。
人工智能技术可以分类,引用UCLA朱松纯的分类,归纳为六个:
①机器学习(各种统计的建模、分析工具和计算的方法)
②计算机视觉(暂且把模式识别,图像处理等问题归入其中)
③认知与推理(包含各种物理和社会常识)
④机器人学(机械、控制、设计、运动规划、任务规划等),像近期波士顿动力公司做了机器人后空翻的演示。
⑤博弈与伦理(多代理人agents的交互、对抗与合作,机器人与社会融合等议题)。
⑥自然语言处理(暂且把语音识别、合成归入其中,包括对话)。
把近几年的大事件,包括自动驾驶,把这些做一些分类,跟人工智能的深度学习技术,包括知识图谱、深度学习、增强学习,这些在行业应用中跟行业技术配合使用。今天提到人工智能就是深度学习,其实这只是人工智能大领域里面很小的一块,事实上还有早期机器学习相关算法的研究,发展到今天,深度学习的技术已经把很多技术做了替代,变得更加前沿的一个方法。
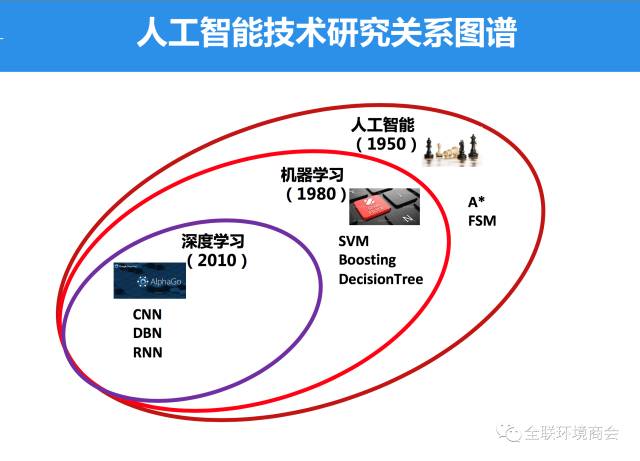
人工智能的三次浪潮与深度学习算法有比较好的契合。1958、1982、1986年分别是人工智能兴起的时候。李国杰院士说过:“人工智能已经炒过几回了,经历了几个夏天和冬天,忽冷忽热;现在终于到了秋天了,是收获的季节了。”
这次人工智能浪潮的兴起,毫无疑问得益于深度学习技术的发展和兴起。深度学习技术发展历程坎坷。20年前,Hinton提出了Neural Network,没有得到热门发展。NN逐渐冷落,SVM和Boosting等不断兴起……Hinton于2006年在《科学》上发表文章,首次提出DL。热点的兴起也离不开背后技术的发展。一方面得益于计算技术的发展和推动,还有就是大数据的发展,两者结合使DL深度学习方法能够发挥更有效的作用。深度学习的基本思想就是构建具有很多隐层的机器学习模型和海量的训练数据,来学习更有用的特征,从而最终提升分类或预测的准确性。
深度学习模型,层次很多,通常有5层、6层,甚至10多层,上百层神经网络,对于技术能力的需求越来越大。在高度发展空间,深度学习类型有很多。针对不同领域,图像、文本、语音识别等等,在实际应用中常常都混合着使用,出现很多灵活的组合方式。根据实际实用问题,选择合适的网络。像很多宽带一样,google tensorflow,Caffe以及MX.NET等深度学习的框架。很多大公司或创业公司都基于这些框架开发自己的产品,做自己的研究。这些框架有不同的优点和缺点。
这些缺点和深度学习的模型是一样的,根据实际问题选择更合适的框架和模型。做个简单总结,Caffe是最早的深度学习框架,科研应用的综合性能好,但主要局限于CNN。MX Net更加注重高效,文档详细,上手很容易,运用也灵活。 Google强力推出的Tensor Flow,很多人跟随这个框架使用,功能很齐全,能够搭建的网络种类更丰富,但综合性能比别的开源框架要差一些。但在某些阶段也不太注重性能。一个有效的解决途径是针对具体应用设计混合型学习框架。
但是目前存在很多的问题,可以通过三个方面来阐述。

第一,产业链。产业链不完整,缺少从国产芯片、平台、应用软件的完整产业链。生态圈不丰富:缺乏CNN、RNN等多种深度学习算法训练库。
第二,平台。缺少对国内处理器、DCU及其他国产加速器的开源服务平台。像跟曙光合作的DCU、寒武纪,都没有一整套开源作为支撑。缺乏覆盖科学研究、经济民生等大规模深度学习训练的数据资源。现在很多信息不共享,比如医院、政府资源,数据看不到,平台做的再好也没有意义。
第三,应用。顶级计算、国产处理器与深度学习应用结合不足。深度学习应用开发和使用门槛高、代价大、效率低、周期长。
针对这些问题,希望能够结合以前在HTC做了一些技术,构建AI创新计算平台,从云计算、大数据、高性能计算这三个层面创造高效、灵活部署的平台,帮助用户快速使用AI的平台。我们希望构建一个面向人工智能应用的开源平台。

这个平台是从顶层到上层,就是SAAS、PAAS、IAAS,一直做到顶层应用产品。高性能所更多是做底层基础平台建设,最底层的IAAS,构建一个统一的开发环境,帮助存储分布式海量数据,以及跟上层资源的调度、算法的联系,还有一些训练服务的标注工具,再上向,就是面向在线服务的软件开发服务和标准接口,再往上就是面向国内行业用户,构建不同行业的应用场景,包括图像识别、视频处理、语音识别等等。在每个层面都有重点,底层的中科曙光GPU,中科院的寒武纪芯片,申威处理器。在国产平台上,构建整套人工智能软件的生态环境,推动平台建设。有分析工具,模型、算法、调度、服务框架,未来陆续将开源平台在社区开放。这是GPU,中科曙光首个DCU处理器面向高性能计算的总体架构,我本人是在核心算法库、软件站,以及框架运用开发层面,围绕底层平台构建开发环境。有一个初步的工作成果,在网上作了开源,有兴趣的人可以看一下。
我们借助这样的工作基础,在全国布置了40多个城市云、10多个先进计算中心,提供全国最大深度学习GPU集群,有一万以上的GPU。还有与应用方一起,构建了全球最大视频深度学习的在线系统,科学院有装置,提供深度学习、人工智能以及大数据支撑服务。
最后,简单介绍一下气象环保大数据分析的工作。如果做气象预报,如何将各种来源数据做整合和训练,预报气象,包括预警和分析。最近做了雾霾相关的预测研究,针对空气质量预测,现在也有一些方法,是基于一些模拟软件,计算指标值,变量,如PM2.5、PM10、SO2、CO、O3等,通过四个空气污染模式(NAQP、CAMX、CMAQ、WRFC),再做拟合。但仍然存在一些问题,比如与观测值差别还较大。在现有模式结果的基础上,如何利用统计、机器学习等方法,提升预报的准确率。
OCF算法基于两个假设,得到两条线,表明假设与实际不符,我们要做的工作就是把这两条线的预测能够更准确,最后能够重合。目前还没有应用更加复杂的方法,还是结合OCF最优化算法,包括算法模块的替换,预测效果还是不错的。

这里有四个图,在90天的时间维度下和120天的时间维度下,看到两个站点预测值与观测值对照图。可以看到绿色(机器学习算法值)的线和蓝色(观测值)重合度还是很高的,两条线趋势变化也是一致的。图中灰色线是最优化算法集合实现的预测,通过简单的机器学习算法能够把空气质量预测应用场景做得更加准确,未来采用更加高效和深度学习方法能够做得更好。
(根据录音整理,未经本人审阅)

|
提交关闭



